Making some models and figures using Melbourne housing data from the dataset anthonypino/melbourne-housing-market. Notes from the first three assignments from dansbeckers course and exposition.
Since this is the first assignment, and since I would much rather automate things, I would like to say that it is worth knowing that the kaggle API has a python client available on PyPI. This may be installed using pip install kaggle or in my case poetry add kaggle.
It turns out that the kaggle library is not the only client available for using kaggle in python modules. There is also a solution called kagglehub. It can be installed like poetry add kagglehub.
from typing import Iterable, Typeimport kagglehubimport pathlibimport ioimport contextlibfrom matplotlib.axes import Axesimport matplotlib.pyplot as pltimport seaborn as sbimport numpy as npimport pandas as pdfrom IPython.display import displayfrom sklearn.tree import DecisionTreeRegressorfrom sklearn.ensemble import RandomForestRegressorfrom sklearn.model_selection import train_test_splitDIR = pathlib.Path(".").resolve()# NOTE: The ``path`` argument does not specify the path downloaded to, but # instead a subpath of the data.DATA_DOWNLOAD_IO = io.StringIO()DATA_ID ="anthonypino/melbourne-housing-market"with contextlib.redirect_stdout(DATA_DOWNLOAD_IO): DATA_DIR = pathlib.Path(kagglehub.dataset_download(DATA_ID))DATA_PATH_LESS = DATA_DIR /"MELBOURNE_HOUSE_PRICES_LESS.csv"DATA_PATH = DATA_DIR /"Melbourne_housing_FULL.csv"
Warning: Looks like you're using an outdated `kagglehub` version, please consider updating (latest version: 0.3.12)
Downloading from https://www.kaggle.com/api/v1/datasets/download/anthonypino/melbourne-housing-market?dataset_version_number=27...
Note that it is necessary to capture stdout if you want your notebook to look nice. The output in DATA_PATH should be a path to the data full data, and (obviously) DATA_PATH_LESS should be a path to the partial data. It will look something like
Description of the dataset in MELBOURNE_HOUSE_PRICES_LESS.csv.
This is roughly what was done on the first assignment but with a different data set (this one came from the example before) the homework assignment. Further the assignment asked for some interpretation of the data set description.
Pandas Refresher
I will go ahead and write about pandas a little more as notes on the next tutorial and for my own review.
The columns of the DataFrame are able to be viewed using the columns attribute:
DATA = pd.read_csv(DATA_PATH)print("Columns:", *list(map(lambda item: f"- `{item}`", DATA)), sep="\n")
pd.core.series.Series is very similar to pd.DataFrame and shares many attributes. For instance, we can describe an individual column:
DATA["Distance"].describe()
count 34856.000000
mean 11.184929
std 6.788892
min 0.000000
25% 6.400000
50% 10.300000
75% 14.000000
max 48.100000
Name: Distance, dtype: float64
Description of the Distance column.
The following block of code confirms the type of DISTANCE and shows the useful attributes of pd.core.series.Series by filtering out methods and attributes that start with an underscore since they are often builtin or private:
Null columns can be removed from the DataFrame using the dropna method. This does not modify in place the DataFrame, rather it returns a new DataFrame (unless the inplace keyword argument is used):
def clean_data(data: pd.DataFrame):"""Clean data and transform category columns into categories.""" data_clean = data.dropna(axis='index')# NOTE: Categories are required for swarm plots. data_clean["Rooms"] = (rooms := data_clean["Rooms"]).astype( pd.CategoricalDtype( categories=list(range(rooms.min() -1, rooms.max() +1)), ordered=True, ) ) data_clean["Bathroom"] = (bathroom := data_clean["Bathroom"]).astype( pd.CategoricalDtype( categories=sorted(set(bathroom.dropna())), ordered=True, ) )return data_cleanDATA_CLEAN = clean_data(DATA)DATA_CLEAN_DESCRIPTION = DATA_CLEAN.describe() # We'll need this later.display(DATA_CLEAN_DESCRIPTION)
/tmp/ipykernel_2592/2604006848.py:7: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data_clean["Rooms"] = (rooms := data_clean["Rooms"]).astype(
/tmp/ipykernel_2592/2604006848.py:13: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
data_clean["Bathroom"] = (bathroom := data_clean["Bathroom"]).astype(
Price
Distance
Postcode
Bedroom2
Car
Landsize
BuildingArea
YearBuilt
Lattitude
Longtitude
Propertycount
count
8.887000e+03
8887.000000
8887.000000
8887.000000
8887.000000
8887.000000
8887.000000
8887.000000
8887.000000
8887.000000
8887.000000
mean
1.092902e+06
11.199887
3111.662653
3.078204
1.692247
523.480365
149.309477
1965.753348
-37.804501
144.991393
7475.940137
std
6.793819e+05
6.813402
112.614268
0.966269
0.975464
1061.324228
87.925580
37.040876
0.090549
0.118919
4375.024364
min
1.310000e+05
0.000000
3000.000000
0.000000
0.000000
0.000000
0.000000
1196.000000
-38.174360
144.423790
249.000000
25%
6.410000e+05
6.400000
3044.000000
2.000000
1.000000
212.000000
100.000000
1945.000000
-37.858560
144.920000
4382.500000
50%
9.000000e+05
10.200000
3084.000000
3.000000
2.000000
478.000000
132.000000
1970.000000
-37.798700
144.998500
6567.000000
75%
1.345000e+06
13.900000
3150.000000
4.000000
2.000000
652.000000
180.000000
2000.000000
-37.748945
145.064560
10331.000000
max
9.000000e+06
47.400000
3977.000000
12.000000
10.000000
42800.000000
3112.000000
2019.000000
-37.407200
145.526350
21650.000000
Description of the data minus null rows.
The axis keyword argument of DataFrame.dropna is used to determine if rows (aka index or 0) or columns (columns or 1) with null values are dropped. From this data a certain number of columns can be selected using a list as an index:
Note that sklearn.model_.train_test_split is used to chunk up the data so that we can compute error in predictions of the model outside of the data that will be used to train it, this is referred to as ‘Out Sample’ data.
‘In Sample’ data is used in the initial error analysis of the model used in this notebook. In the section after that, ‘Out Sample’ data is used to assess the accuracy of the model. Finally, predictions are made for entries that did not have a price.
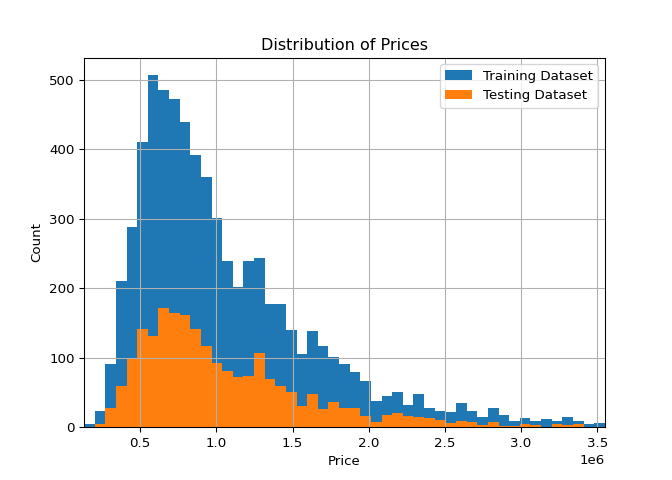
It is also useful to look at the price distribution of both the training and testing datasets. This is easy to do with pd.DataFrame.hist:
Distribution of prices in test and training datasets.
Predicting Prices with a Tree Model
About scikit-learn Learn
It is easy to install scikit-learn using poetry or pip like
poetry add scikit-learn
Model Implementation
The following cell will predict the prices of houses for which the price is known:
def create_model(features: pd.DataFrame, target, /, cls: Type =DecisionTreeRegressor, **kwargs): tree = cls(random_state=1, **kwargs) tree.fit(features, target)return treeTREE = create_model(DATA_FEATURES, DATA_TARGET)
Model In Sample Error Analysis
Now we should measure the accuracy of the model against some in sample data. This is done to contrast against our out sample analysis in the next section of this notebook. The following function creates a dataframe for comparison:
def create_price_compare( tree, data: pd.DataFrame,*, price =None,):"""Create a dataframe with price, actual price, error, error_percent and feature columns.""" data_features = data[DATA_FEATURES_COLUMNS] price_actual = price if price isnotNoneelse data["Price"] price_predictions = tree.predict(data_features) error = np.array(list( actual - predictedfor predicted, actual inzip(price_predictions, price_actual) ) ) df = pd.DataFrame( {"predicted": price_predictions,"actual": price_actual, "error": error,"error_percent": 100*abs(error / price_actual) } ) df = df.sort_values(by="error_percent") df = df.join(data_features)return dfPRICE_COMPARE = create_price_compare(TREE, DATA_CLEAN)
count 8887.000000
mean 5.749109
std 20.797978
min 0.000000
25% 0.000000
50% 0.000000
75% 0.773343
max 1284.615385
Name: error_percent, dtype: float64
Description of PRICE_COMPARE["error_percent"].
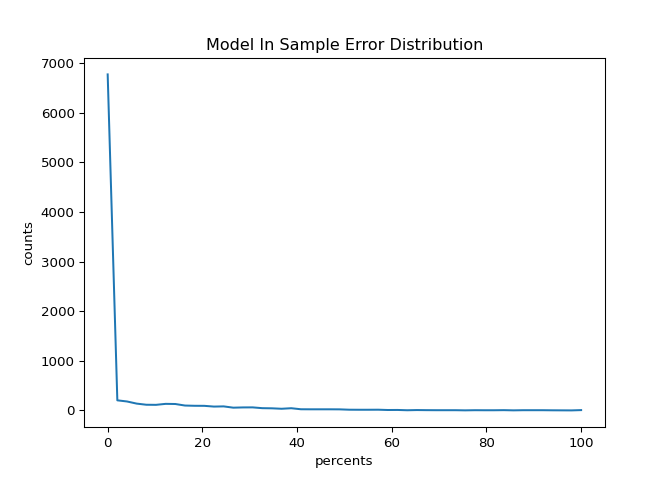
The description indicates that the mean error is reasonably low. Let’s now plot the distribution of prediction errors within the in sample data:
This is good (as most of the error is distributed between \(0\) and \(5\) percent). However, as will be shown in the next section, this cannot be expected for any out sample data.
Model Out Sample Error Analysis
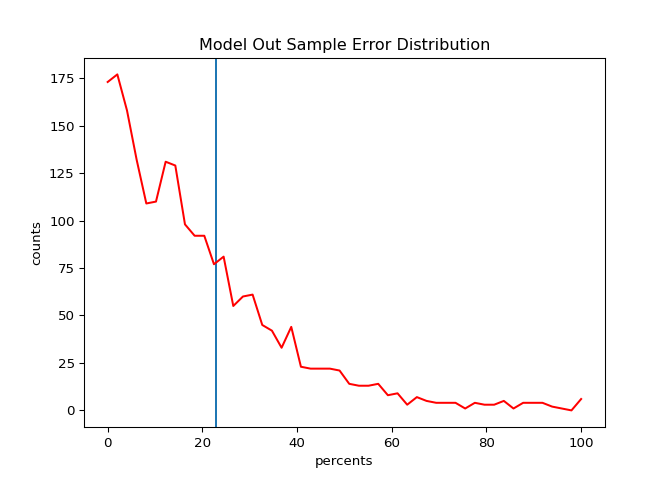
Conveniently, the functions above can be used for our out sample data. This is as easy as
This plot does not look at all like the in sample error, which decays immediately with its spike contained under \(5\) percent. It would indicate that error is generally high on the out sample data, implying that there is some room for improvement. The vertical line is included to show the \(mnae\), the mean normalized absolute error (as a percentage).
Improving the Model
After running the model against some out sample data, it is clear that the model does not perform well right out of the box. If we were to only look at in sample data, this would not be apparent.
It is possible to modify change model parameters to attempt to tune the model. To make comparisons, we should combine the above script into a function to get the analysis dataframe for each tree.
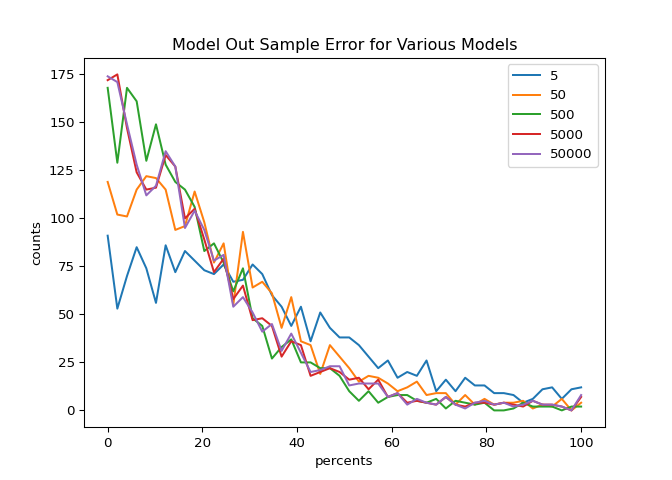
Out sample error distributions for models with various max_leaf_node values.
The best curves should have a strong peak towards the front (implying that error tends to lower for more entries) and decay rapidly. The initial model would appear to be reasonable fit because it matches the best curves (where max_leaf_nodes is \(5000\) and \(50000\)).
It would appear that there is not much room for improvement of the model along parameter of max_leaf_nodes. An objective choice of the number of leaf nodes can be done by minimizing the mean normalized absolute error:
The minimized mnae (`0.21206521792307836`) has `max_leaf_nodes = 500`.
From this we will take the corresponding tree as the best model:
TREE = TREES[MAX_LEAF_NODES.index(BEST)]
Making Predictions with the Model
The goal here is to plot and compare price predictions on the rows of DATA that did not have a price and make some pretty plots. Rows with null columns can be found like follows:
Description of the dataset rows with no price specified.
This works because DATA["Price"] should contain the indices of the respective rows within the dataframe, making it a suitable index. In the description it is clear that this worked because the price stats are either zero of NaN. Now it is time to attempt to fill in these values:
Note that TREE will reject the input if it contains all of columns and not just the feature columns, thus why DATA_PRICE_NULL is indexed. The description of this dataframe should be reasonable comparable to the data description of DATA_CLEAN.
def create_price_predictions_compare(data_clean: pd.DataFrame, data_interpolated: pd.DataFrame): interpolated = data_interpolated["Price"].describe() actual = data_clean["Price"].describe()# error = interpolated - actualreturn pd.DataFrame( {"predicted": interpolated,"actual": actual,# "error": error,# "error_percent": 100 * (error / actual), } )# NOTE: The last object in a code cell is displayed by default, thus why this# dataframe is created yet not assigned.create_price_predictions_compare(DATA_CLEAN, DATA_PRICE_NULL_PREDICTIONS)
predicted
actual
count
7.610000e+03
8.887000e+03
mean
1.348987e+06
1.092902e+06
std
7.938628e+05
6.793819e+05
min
3.663929e+05
1.310000e+05
25%
8.003333e+05
6.410000e+05
50%
1.185000e+06
9.000000e+05
75%
1.675000e+06
1.345000e+06
max
9.000000e+06
9.000000e+06
Comparison of interpolated data and completed data descriptions.
Now that we know the data descriptions are reasonable (by comparing the magnitude of any of the provided data) we can combine the predictions and the clean data and label them as being estimated or not in the Estimated column.
def create_data_completed(data_clean: pd.DataFrame, data_interpolated: pd.DataFrame, ) -> pd.DataFrame:# NOTE: Create dataframe with features and prices, add that it is not estimated data_estimated_not = data_clean[[*DATA_FEATURES_COLUMNS, "Price"]].copy() data_estimated_not["Estimated"] = pd.Series(data=(Falsefor _ inrange(len(data_clean))))# NOTE: Add estimated to the estimated prices dataframe. data_interpolated = data_interpolated.copy() data_interpolated["Estimated"]= pd.Series(data=(Truefor _ inrange(len(data_interpolated))))return pd.concat((data_estimated_not, data_interpolated)) # type: ignoreDATA_COMPLETED = create_data_completed(DATA_CLEAN, DATA_PRICE_NULL_PREDICTIONS)
This will allow us to generate some nice swarm plots in seaborn.
/quarto/.venv/lib/python3.11/site-packages/seaborn/categorical.py:3399: UserWarning: 16.1% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
/quarto/.venv/lib/python3.11/site-packages/seaborn/categorical.py:3399: UserWarning: 13.1% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
/quarto/.venv/lib/python3.11/site-packages/seaborn/categorical.py:3399: UserWarning: 15.2% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
/quarto/.venv/lib/python3.11/site-packages/seaborn/categorical.py:3399: UserWarning: 18.7% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
/quarto/.venv/lib/python3.11/site-packages/seaborn/categorical.py:3399: UserWarning: 14.5% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
/quarto/.venv/lib/python3.11/site-packages/seaborn/categorical.py:3399: UserWarning: 17.2% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
/quarto/.venv/lib/python3.11/site-packages/seaborn/categorical.py:3399: UserWarning: 5.7% of the points cannot be placed; you may want to decrease the size of the markers or use stripplot.
warnings.warn(msg, UserWarning)
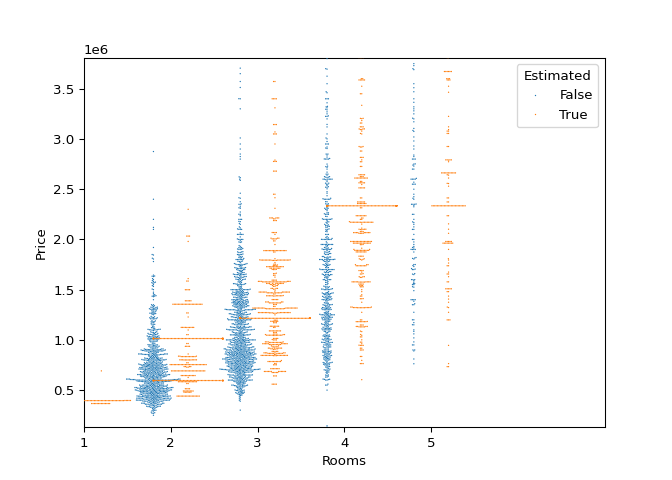
Swarm Plot by Rooms
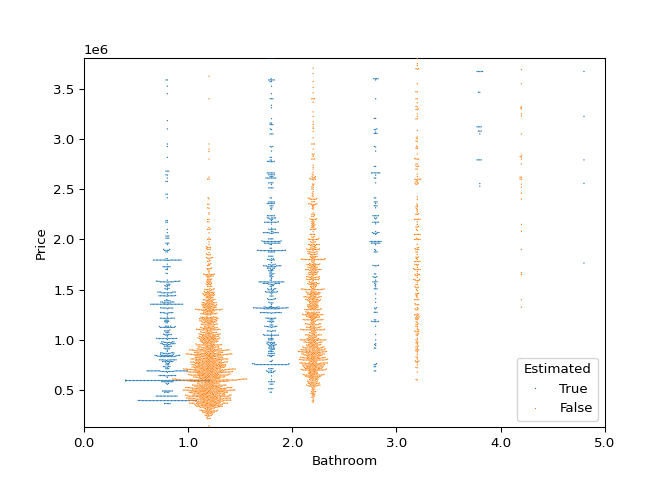
Swarm Plot by Bathrooms.
It is interesting to notice the stacking of identical values on the prediction side. This would mean that the decision tree would follow a path down to the same node each time, an inherent problem with decision trees. In the next section an attempt to remedy this is made.
Making Predictions With an Ensemble of Trees
A forest is simply many trees. To try to better the predictions made by a tree and resolve over-fitting and under-fitting with some sort of consensus many trees are used and their results are averaged. sklearn.ensemble.RandomForestRegressor may be constructed and trained in exactly the same way that DecisionTreeRegressor is, e.g.